Qu’est-ce qu’un rapport sur les microservices ?
On parle de rapports sur les microservices lorsque les rapports sont créés à partir d’une architecture de microservices. Bien que l’architecture de microservices offre de nombreux avantages aux organisations, elle pose des défis en matière de reporting en raison de sa nature fragmentée.

Qu’est-ce qu’un modèle de microservice ?
Pour comprendre les rapports sur les microservices, il faut bien comprendre l’architecture qui les sous-tend. Une architecture de microservices est un système basé sur le cloud dans lequel le système logiciel d’une organisation est constitué d’un certain nombre de composants plus petits. Ces services ou composants peuvent être déployés indépendamment les uns des autres, mais sont étroitement liés entre eux, généralement à l’aide d’interfaces de programmation d’applications (API). À l’instar du fonctionnement d’un cerveau, les services sont comme des cellules cérébrales, reliées entre elles par des synapses (API) qui permettent la communication d’informations d’une cellule à l’autre. Chacun de ces microservices est responsable d’une action ou d’une exigence spécifique et se déploie automatiquement en cas de besoin.
Ces services disposent tous de leur propre base de données et ne partagent pas les informations d’une base de données centrale comme le font les autres systèmes. C’est ce que l’on appelle être « lié », c’est-à-dire que tout ce qui est nécessaire au fonctionnement de ce service est lié à l’application.
Ce caractère limité est important pour éviter tout couplage involontaire de services. Si les schémas de données sont partagés entre les services, toute modification apportée à l’un d’entre eux doit être répercutée sur tous les schémas de données sous-jacents. En gardant tout séparé, cela signifie que les changements sont limités, que les services sont totalement autonomes et que l’architecture conserve toute son agilité.
Les organisations choisissent d’utiliser des microservices pour diverses raisons. Les applications indépendantes peuvent être facilement mises à jour et modifiées, et de nouvelles fonctionnalités peuvent être ajoutées rapidement. Différentes équipes peuvent exploiter différentes piles d’applications ou de programmes qui fonctionnent sous un même toit, ce qui confère une grande souplesse au modèle d’entreprise.
Cette architecture peut également s’avérer très rentable. Les API sont gratuites ou peu coûteuses ; les programmes individuels peuvent être des logiciels en tant que service (SaaS) et des utilisateurs-payeurs. Ils sont entièrement modulables et ne nécessitent pas d’infrastructure importante.
Les entreprises qui utilisent l’architecture de microservices sont notamment Amazon, Netflix, Uber et SoundCloud. Il s’agit véritablement d’une structure logicielle qui permet une flexibilité et une évolutivité énormes dans un modèle d’entreprise.
Cependant, les inconvénients des microservices sont que les API créent plus de risques de cyberattaques et la diversité des langages de programmation et de communication entre les applications. Mais le problème le plus important concerne les rapports. Chaque application ou programme possède sa propre base de données. Alors, comment un utilisateur peut-il extraire toutes les données des bases de données pour produire des rapports ? Ce concept d’extraction de données à partir de chaque application ne préserve pas la valeur fondamentale du contexte délimité.
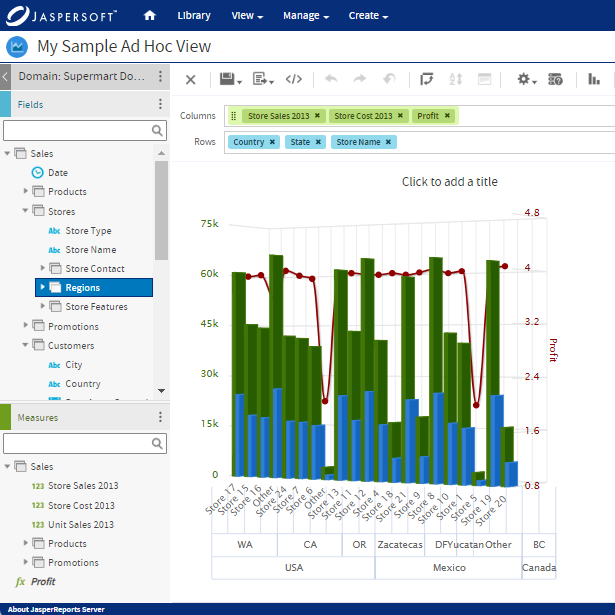
Rapports sur les microservices
Si une organisation utilise une architecture de microservices, un modèle simple pourrait supposer qu’elle dispose de différents programmes pour :
- Finances et facturation
- Outil de flux de travail
- Programme de vente
- Système de paie
Chacun de ces microservices possède sa propre base de données. Les API permettent de relier ces programmes entre eux afin qu’ils puissent fonctionner sous une seule interface. Cependant, les problèmes commencent lorsqu’il s’agit de produire des rapports qui tirent des données de plusieurs bases de données.
C’est le cas, par exemple, lorsque les salaires sont basés sur des travaux achevés et facturés. L’outil financier doit avoir accès à l’outil de gestion des flux de travail, et ce n’est qu’à cette condition que l’outil de paie dispose d’informations exactes pour payer les salariés. Si une entreprise souhaite produire un rapport indiquant les travaux en cours par rapport aux ventes réalisées au cours du mois, elle doit accéder à trois programmes différents.
Cela devient encore plus complexe lorsqu’il y a beaucoup, beaucoup de microservices. Netflix, par exemple, reçoit plus de deux milliards de demandes d’API par jour, réparties sur plus de 700 microservices. Uber utilise plus de 1 300 microservices. Avec un grand nombre de services, l’établissement de rapports devient plus complexe.
Défis liés à l’établissement de rapports sur les microservices
Les rapports sur les microservices posent trois grands problèmes.
Questions de performance
Si une entreprise reçoit deux milliards de demandes d’API par jour pour des fonctions commerciales, imaginez la charge supplémentaire que représente la création de rapports. Si un outil de rapport tire des données de plusieurs sources, souvent plusieurs centaines de fois par jour, comment cela va-t-il affecter le système ? Cela va considérablement ralentir les processus, voire les interrompre.
Anti-modèle
L’idée même de l’architecture de microservice est que chaque service est limité. En d’autres termes, chaque application est un mini-programme en soi. Il contient tout ce dont il a besoin et fonctionne à l’intérieur de ses propres limites. Il n’a besoin d’accéder à rien d’autre pour remplir ses fonctions.
Lorsque le reporting exige que les services partagent leurs bases de données, il devient un anti-modèle.
Différents modèles et types de données
Si chaque service est écrit dans un langage de programmation différent, il faut une couche supplémentaire de communication entre les services pour permettre la compréhension. Ensuite, si les données ne sont pas présentées sous la même forme qu’une autre, elles doivent être manipulées automatiquement afin d’être assimilées et utilisées par l’outil de reporting.
Données contradictoires
Comme chaque service dispose de sa propre base de données, il peut y avoir des redondances, des duplications ou des conflits de données. Par exemple, si un fournisseur est également un client et qu’ils ont la même adresse physique, mais que l’une d’entre elles est incorrecte dans le système, cela peut entraîner des problèmes dans la compilation des données.
Ce qu’exige le rapport sur les microservices
Un bon rapport est essentiel à la santé et à la croissance d’une organisation. Un bon système d’information doit comporter les éléments suivants :
Simplicité d’utilisation
Les rapports doivent être simples à exécuter. À l’aide d’un tableau de bord central, il devrait être facile de sélectionner les paramètres et d’appliquer les données pertinentes dans les rapports. Comme les microservices relèvent tous d’un tableau de bord, il est facile d’y parvenir.
Une seule source de vérité
Pour que les rapports soient exacts, les données doivent être correctes. Il doit y avoir une seule source de vérité pour les données, sans doublons, informations anciennes ou incorrectes, et tout ce dont le rapport a besoin doit s’y trouver. C’est le plus grand défi pour les microservices, car les applications sont séparées et faiblement couplées.
rapides
Dans un monde où tout est instantané, les rapports doivent être actualisés. Lorsqu’il y a des soldes pendant les fêtes, un changement d’environnement de travail ou un comportement différent de la part des clients, ces changements doivent être notés et pris en compte dès que possible. Cela pose également des problèmes au modèle des microservices, en fonction de la manière dont les données sont accessibles.
Rapide
Si l’exécution d’un rapport prend des heures et mobilise des ressources, il s’agit d’un obstacle important à la mise en place de systèmes de rapports efficaces. L’exécution simultanée de milliers d’API pour accéder aux données constitue un obstacle considérable à l’établissement de bons rapports dans une architecture de microservices.
Automatisation
Le système d’obtention des données, d’extraction, de traitement et de production des rapports doit être hautement automatisé. Les utilisateurs ne doivent pas avoir à accéder au back-end, à exécuter des opérations manuelles ou à effectuer des manipulations manuelles des données.
Facile à comprendre
La présentation de rapports sous forme de lignes de données granulaires n’est pas toujours nécessaire et n’est pas non plus la meilleure façon de comprendre les informations. Pour que les rapports soient facilement assimilés par un large éventail d’utilisateurs, ils doivent être présentés sous forme de graphiques, de tableaux et de diagrammes qui montrent rapidement les tendances, les schémas et les chiffres.
La possibilité d’approfondir les connaissances
Si un utilisateur ou un présentateur dispose d’un simple graphique, mais qu’il a besoin de comprendre comment et pourquoi quelque chose s’est produit, il doit y avoir une fonctionnalité permettant aux utilisateurs de voir des données granulaires. Les organisations doivent être en mesure d’explorer facilement les informations afin d’identifier les problèmes, les points forts et les anomalies.
Fonctionnalité d’intelligence artificielle (IA)
Il ne sert à rien de disposer de données si l’organisation ne peut pas en tirer des améliorations exploitables. Pour permettre cette fonction, il faut disposer d’une fonctionnalité d’IA afin que les données deviennent des informations et des prédictions. Une fois les données collectées, il est facile d’ajouter des fonctionnalités d’IA grâce à la nature segmentée des microservices.
Solutions potentielles pour les rapports sur les microservices
Il existe un certain nombre d’options pour permettre l’établissement de rapports dans une architecture de microservices. La solution adéquate pour une organisation dépend de nombreux facteurs différents, et la réponse n’est pas unique.
La première étape consiste à trouver les services adéquats. Le modèle des microservices signifie que chaque tâche nécessite une application ou un programme différent. Ces microservices seront placés à côté de toutes les autres applications et de tous les autres programmes. Il est probable qu’une entreprise aura besoin d’un service qui extrait ou reçoit des données, d’un autre avec des fonctions de reporting, puis d’un autre avec des capacités d’IA.
Une fois ces services installés, il s’agit d’extraire les données des autres microservices et de créer les rapports nécessaires.
Connexions directes aux bases de données
Le service de reporting se connecte directement aux autres microservices, récupère les informations pertinentes dans leurs bases de données et les achemine vers un entrepôt de données. C’est simple, mais cela signifie que toute modification du schéma d’une base de données nécessitera également une modification du service de reporting. Il rompt également le contexte délimité qui est si important dans l’architecture des microservices.
Service d’agrégation Modèle HTTP Pull
Ce service utilise des API pour se connecter aux microservices concernés. Il appelle les informations requises et les achemine par le biais de l’entrepôt de données et de l’outil de reporting. Cependant, cette méthode est sujette à des performances lentes et à des erreurs 504 de dépassement de délai. Chaque service supplémentaire avec lequel il doit communiquer ajoute une charge supplémentaire au système, agrégeant de multiples sources de données qui créent d’énormes problèmes de performance.
Une fois de plus, comme il s’agit d’un modèle à tirage, il viole le contexte délimité.
Batch Pull et base de données dédiée
Dans cette stratégie, une commande est exécutée selon un calendrier et les informations sont extraites par lots de toutes les bases de données de microservices concernées. Ces données sont ensuite mises à jour en masse dans la base de données des rapports. Toutefois, comme pour la connexion directe à la base de données, toute modification du schéma peut interrompre l’ensemble du travail par lots. Chaque fois que le schéma est modifié, les fonctions de traitement par lots doivent également être mises à jour.
L’autre problème est qu’en tant que modèle d’attraction, il est contraire au contexte limité et peut ne pas aboutir à un rapport en temps voulu. Si la demande d’extraction est liée au moment où la charge est la plus faible, à 2 heures du matin, il n’y a qu’une seule mise à jour par jour.
Base de données dédiée avec poussée d’événements asynchrones
Cette méthode est plus compliquée, mais elle donne de meilleurs résultats et n’enfreint pas le modèle limité. Un microservice de traitement des événements reçoit des mises à jour lorsque des éléments d’un autre service sont mis à jour ou modifiés. L’application, plutôt que de recevoir des informations, envoie des notifications d’événements. Cela signifie qu’un service de saisie des données est informé de toute mise à jour pertinente et que la base de données est mise à jour. À partir de là, un service de reporting peut exécuter les rapports nécessaires.
Les avantages de cette méthode de reporting sont les suivants :
- Préserver les principes de l’architecture délimitée des microservices. Le service de signalement n’écoute pas les applications et n’extrait pas d’informations.
- Veiller à ce que les rapports qui en résultent soient à jour parce que le service de rapport est informé des événements ou des mises à jour d’informations.
- Filtrer les informations qui ne sont pas nécessaires dans l’ensemble du service de saisie des données.
- Agrégation des données sous une forme que le service de rapport peut utiliser par l’intermédiaire du service de capture des données.
- Fournir des rapports asynchrones afin d’éviter les charges de traitement lourdes, les retards ou le couplage temporel.
Comment résoudre les conflits de données ?
Comme il pourrait y avoir littéralement des milliers de bases de données, il est presque certain qu’il y aura des doublons de données, ou des données incorrectes ou erronées. Il est important de résoudre ce problème pour créer des rapports précis. Il existe plusieurs solutions pour relever ce défi.
Un service de mise à jour des bases de données
S’il existe un service intermédiaire qui sait quand une information est mise à jour, il peut transmettre cette mise à jour aux autres services. Par exemple, si l’adresse physique d’un client a été mise à jour, cette information est répercutée dans toutes les instances des informations relatives à ce client. Cela peut s’avérer incroyablement complexe et nécessiter plus de bande passante dans le système, et c’est un contre-modèle.
Choisissez une seule source de vérité pour chaque type de données
Étant donné que chaque service de cette architecture exécute une seule tâche, la base de données qui lui est consacrée ne doit pas être exhaustive. Le service de facturation a besoin de connaître l’adresse postale, tandis que le service des ventes a besoin de l’adresse physique pour expédier le produit. Désignez un service qui sera la source unique de vérité pour cette donnée.
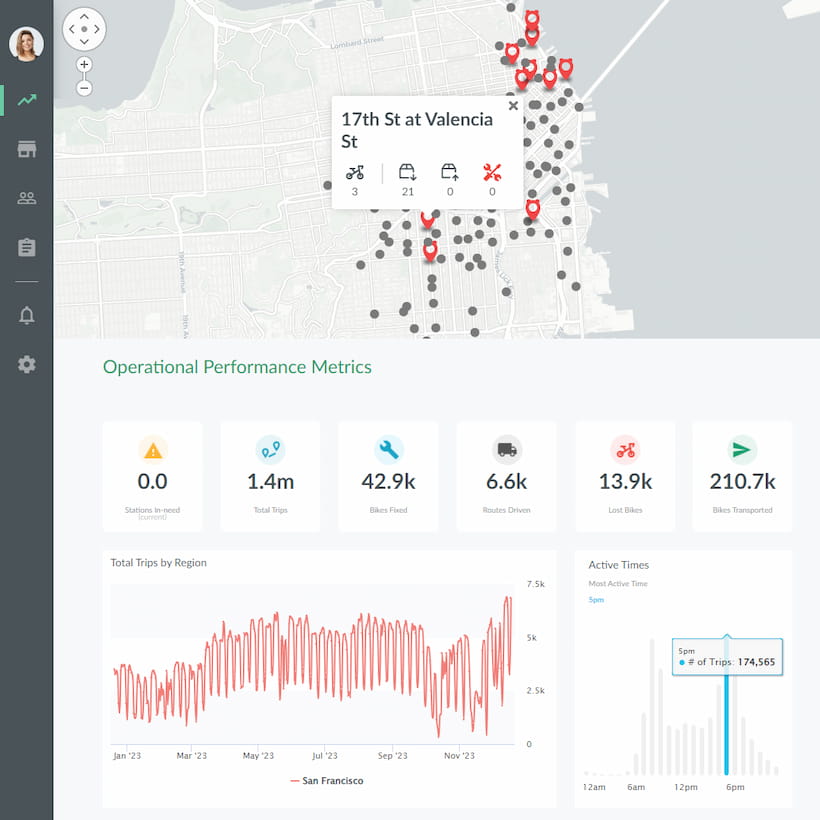
<h2>How to Implement Ad Hoc Reporting</h2>
<h3>Get Your Data Sorted</h3>
This is a mammoth project and requires an overhaul of all your computer systems. Start with a data governance strategy that complies with the GDPR and other relevant laws. Bring all your data together in one centralized location. Put data management systems in place that ensure people can only access the data that they need to. Remove data silos and plan for data consistency across the entire organization.
<h3>Provide Training</h3>
Although ad hoc reporting tools should be intuitive, managers and employees must be shown how they can get the most from the functionality. Rather than “how” training, this is “why” training such as how to select parameters for reports. Training people isn’t just about the software but about how to use data for optimum outcomes.
<h3>Have the Right Tools for the Job</h3>
Choosing the right software is vital to the success of ad hoc reporting. Consider these factors when making decisions about the best options for the organization:
- Access. The tool should be able to funnel multiple channels of data into one place rather than running multiple queries.
- Visualization. Humans are far better at interpreting data when it is in visual form. A great ad hoc reporting tool will offer the ability to present information in charts, tables, graphs, and even pictographs.
- Simple to use. Empower employees to create their own reports easily. Do not create any barriers to successful implementation or ongoing use.
- Scalable. Whether the organization has hundreds of employees or just two, ad hoc reporting tools should be able to grow with the business. That is not just growth in terms of numbers, but also in terms of functionality and ability to manage growing volumes of data.
- Cloud-based. Having reporting systems (and the data) based in the cloud adds functionality and the ability for employees to access and process information regardless of physical location.
<h2>Ad Hoc Reporting is What Your Organization Needs</h2>
While canned reporting and Excel offer some reporting functionality, it is not enough. For a full spectrum of reporting functionality, ad hoc reports are required. These reports give the flexibility to identify and resolve a range of business problems, allowing for data-backed decisions.
Rapports sur les microservices avec Jaspersoft
Ressources associées
Jaspersoft in Action: Embedded BI Demo
See everything Jaspersoft has to offer – from creating beautiful data visualizations and dashboards to embedding them into your application.
Back to Basics: Reporting 101
Discover the fundamentals of delivering reporting to users wherever they are and in a variety of formats.